Tales from the inference land
The previous post described my new local inference and training benchmark - Inference Arena. We talked about the list of models, the platforms, and the metrics captured. Perhaps the most interesting part of that post was about the results, and I want to expand more on it here.
Disclosure: I’m the author of Meganeura, one of the tested frameworks. I’ve tried to keep the methodology honest — judge for yourself. Will announce properly in a separate post.
Apple
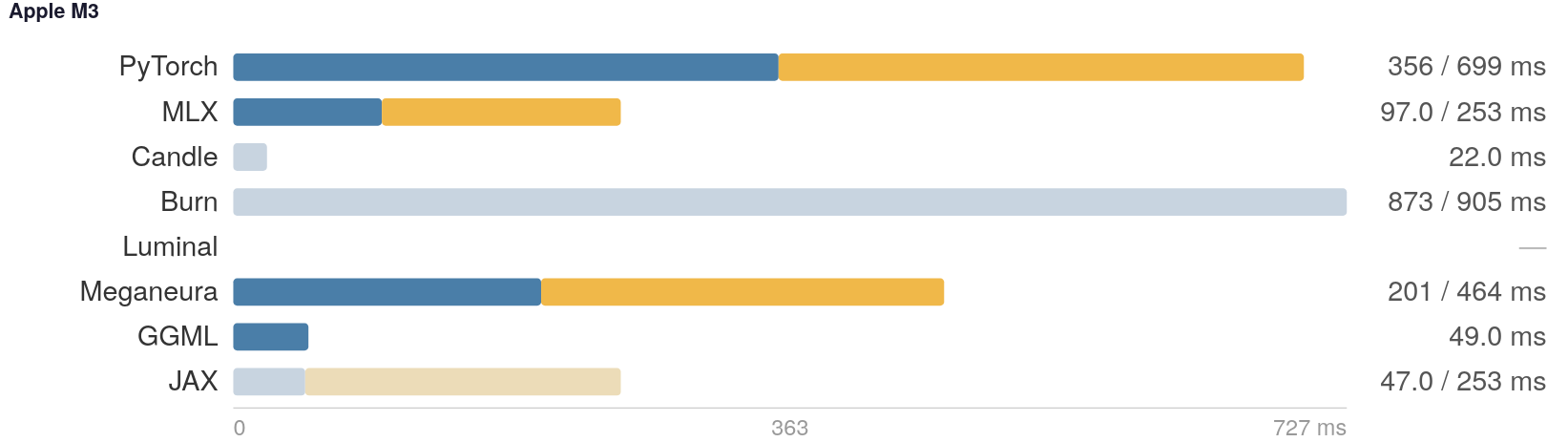
The Apple garden shows a lot of variety in the results. While PyTorch fully supports this platform, it’s based on Metal Performance Shaders. It runs significantly slower than Apple’s MLX framework, which is specifically designed for ML workloads. We aren’t talking 20% here - it’s more than 3x slower on LLM (Large Language Model), 10x slower on VLA (Vision-Language-Action), and 50x on SD (Stable Diffusion). That last number is likely very sensitive to batch size and is first on my list to re-evaluate. At the same time, JAX is showing parity on Apple since it uses MLX under the hood. And Llama.cpp (as “GGML” in the tables) is even faster than MLX on the LLM bench, unlike its performance on Linux/CUDA where it’s 6x slower than PyTorch.
AMD

My main machine is an AMD Framework 13, which supports ROCm. However, it’s missing from a mini-PC I have with Radeon 780M - a popular integrated GPU from 2024 (just 2 years ago). I didn’t include it in the results because one of the frameworks crashes the bench for good - need to look more into it.
Performance-wise, there is a room for improvement in ROCm stack. It’s strongly yielding to ONNX RT and Meganeura on VLA (Vision-Language-Action models) and LLMs (Large Language Models) respectively. This rough state is not limited to APUs: it’s also seen on Radeon RX 7900 XT discreet GPU, which I just acquired for testing.
PyTorch reach
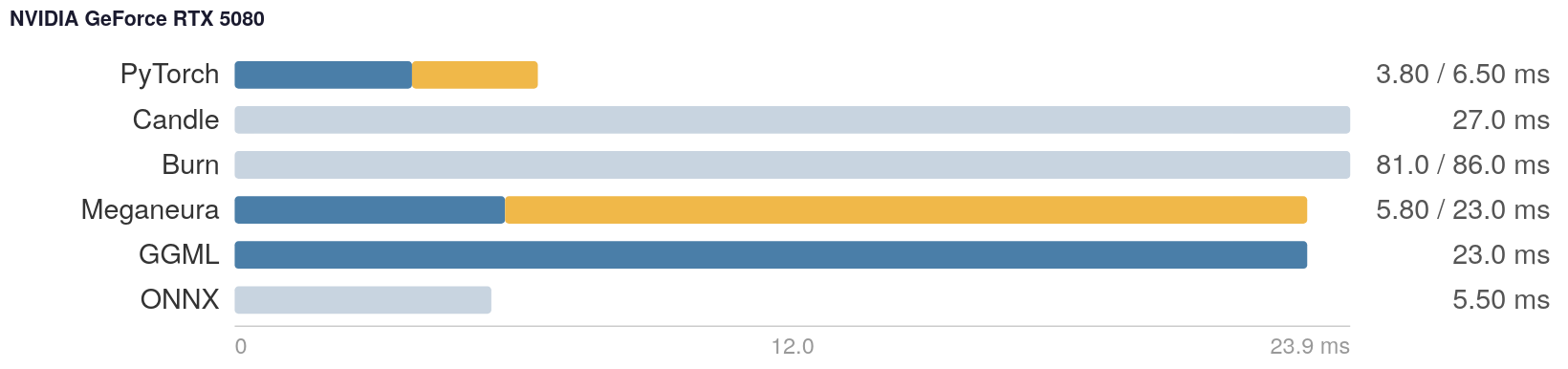
PyTorch is the king on NVIDIA/Linux: slightly faster than ONNX RT (for inference), significantly faster than Llama.cpp, and ahead of anything written in Rust so far.
What I found annoying is to always think about capturing the CUDA graphs and compiling the model to get fast inference. CUDA-graphing is basically pre-recording all GPU commands into a command buffer that gets re-used. This saves CPU costs of dispatching the kernels, which are quite significant in Python. Compiling the model is a process of graph optimization: fusing the kernels, reordering operations. Coming from the graphics land this seems unnecessary: nobody in sane mind would do eager shader compilation and workload scheduling every single frame in a video game. We just create pipelines early (or on demand) and re-use.
On other platforms, PyTorch support is a hit and miss:
- On Windows, PyTorch was not able to compile the model, since Triton - the actual GPU optimizer (and a separate language, no less!) by OpenAI used as the backend - doesn’t support the windowed OS.
- It didn’t work on Intel “Raptor Lake” iGPU (can be seen in the new Framework 12) at all for me via the XPU backend.
- No GPU acceleration on AMD’s Radeon 780M as mentioned.

Deployment struggle
The deployment story is worrisome. I didn’t manage to build a “requirements.txt” file that would naturally support PyTorch on all backends that it cares about. It’s a bit of a mess with all python frameworks, e.g. ONNX RT’s “onnxruntime-gpu” yields to “onnxruntime” (the CPU backend) if both are installed. My “.venv” folder for Windows/NVIDIA is 7Gb in size, with Torch taking 2/3 of that - let that sink in. It’s safe to assume that you’d use PyTorch for development only and deploy to edge devices running inference on an exported model of sorts.
In Rust ecosystem, deployment is easier: just grab a static executable and roll. The established frameworks are Burn (32Mb executable) and Candle (5Mb), with Luminal (8Mb) and Meganeura (16Mb) being dark horses. I benchmarked with correctness gating, and so far I haven’t gotten a good signal from the leaders. In the LLM test their output loss was too far from PyTorch, which makes the actual timings less relevant. Area of improvement for the benchmark.
Magical barriers
The synchronization model of CUDA is different from Vulkan. CUDA has streams where Vulkan has queues. However, within a stream CUDA considers every operation effectively depending on all the previous ones. I find it highly peculiar, since it’s a very defensive stance that would be a better fit for some WebGPU API, not the fight-for-every-millisecond world that CUDA is in. I suspected one of the two things is right: either the NVIDIA driver is able to omit those dependencies in practice by tracking all of the kernel-to-kernel dependencies. Or CUDA is just weird, and maybe we can get faster with Vulkan since we can carefully place split barriers as we deem necessary. Naive, but worth checking. So far, based on Meganeura optimization process and the numbers reached, it appears to me that one can get pretty close with Vulkan. E.g. SD inference is practically on par with PyTorch/CUDA, which means that even if the driver has magic, it still comes down to essentially an L1 or L2 cache flush where appropriate, and Vulkan barriers allow you to control that. Let this be a drop of optimism for my graphics engineer colleagues entering the AI era.