Experiments in ReSTIR land
In 2020, NVidia research group published Spatiotemporal reservoir resampling for real-time ray tracing with dynamic direct lighting. By that time, NVidia had already been selling hardware with hardware ray-tracing support, and there were a few flagship applications for it, like Quake2 RTX. However, sampling was still hard, and a new class of algorithms was needed. ReSTIR brought significant improvement to sampling quality and made ray tracing more viable for real-time applications.
Initially, I implemented ReSTIR in a learning TUI application rs-voir:

Then I started playing with it in 3D and naturally generated a few ideas on how to improve it. This post is sharing the experience of trying out those ideas. TL;DR: nothing worked
Setup
Primary system: Windows, NVIDIA GeForce RTX 3050, driver 551.52
Secondary system: Linux, AMD Radeon 6850U
Implementation:
- “VK_KHR_acceleration_structure” + “VK_KHR_ray_query”, no ray-tracing pipelines
- diffuse-only materials (via Lambertian model)
- 1 env map sample (canonical) + 1 temporal reuse + 1 spatial reuse by default, only direct illumination
- Rust + WGSL on blade-graphics
For benchmarking, I was loading the Intel’s Sponza scene (base only). Rendering was done in windowed full-screen, 2560x1440 resolution. The baseline time for ray-tracing with denoising was around 15ms.
Experiment: group-local ReSTIR
I observed that we have a lot of VRAM traffic for loading reservoirs and G-buffers from the samples that are re-used. I asked “can we use workgroup memory for this?” and dove into this experiment. The idea is to do everything locally within the workgroup.
The first blocker hit me when running on the AMD system: any workgroup sizes above 32 resulted in a crash on startup. I found no explanation to this and assumed it to be a driver bug. Obviously, a bigger workgroup would make it easier to re-use samples. But OK, maybe we can be smarter about small groups… Naively, it was clear that the spatial re-use becomes inefficient if locked to a 4x8 pixel region. I figured that we could interlace pixel rows and columns within a workgroup, we could change its arrangement every frame, and we could offset it differently. In the scheme I implemented, the pixel space was split into clusters, where each cluster has a fixed number of workgroups that split it differently every frame, like this:
After a couple of busy evenings, I was happy to see it working. All the reservoirs and G-buffers lived in local memory:
struct PixelCache {
surface: Surface,
reservoir: StoredReservoir,
world_pos: vec3<f32>,
}
var<workgroup> pixel_cache: array<PixelCache, GROUP_SIZE_TOTAL>;
However, the performance was surprisingly unaffected. While VRAM throughput got reduced (from 78% to 56%), the occupancy went down (from 33% to about 30%). It seemed like a great idea in theory… As for the analysis and explanation:
- the idea of merging everything in one big compute shader goes across the optimization of splitting the work into smaller stages. One big shader is more difficult to schedule and mix with other work on GPU.
- taking advantage of workgroup memory may cause lower occupancy. It’s a trade-off between occupancy and VRAM throughput.
Experiments: merged G-buffer and temporal accumulaton
G-buffer: blade PR#176
As a part of the “group-local” experiment, I tried to merge all the stages into one. The baseline was:
- fill gbuffer: 2.44ms
- ray trace: 9.77ms
- temporal accumulation: 0.83 ms
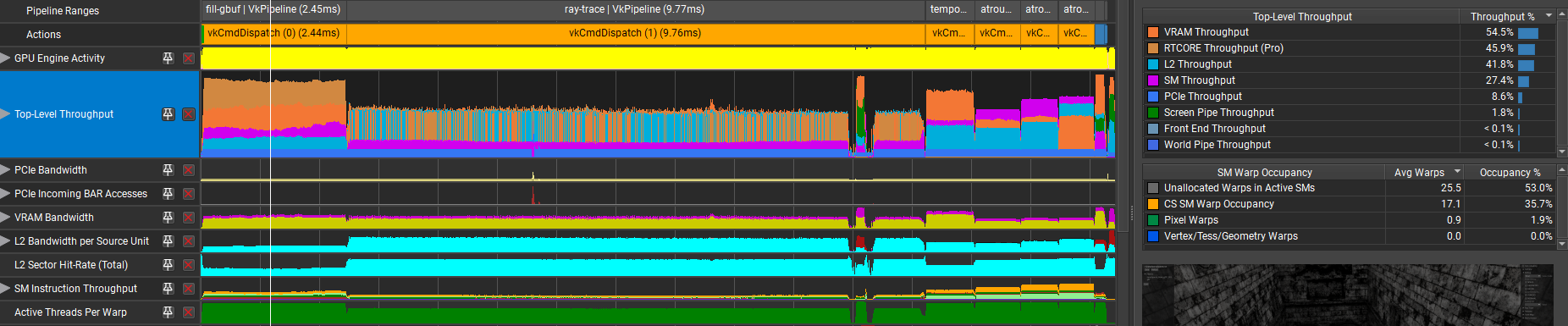
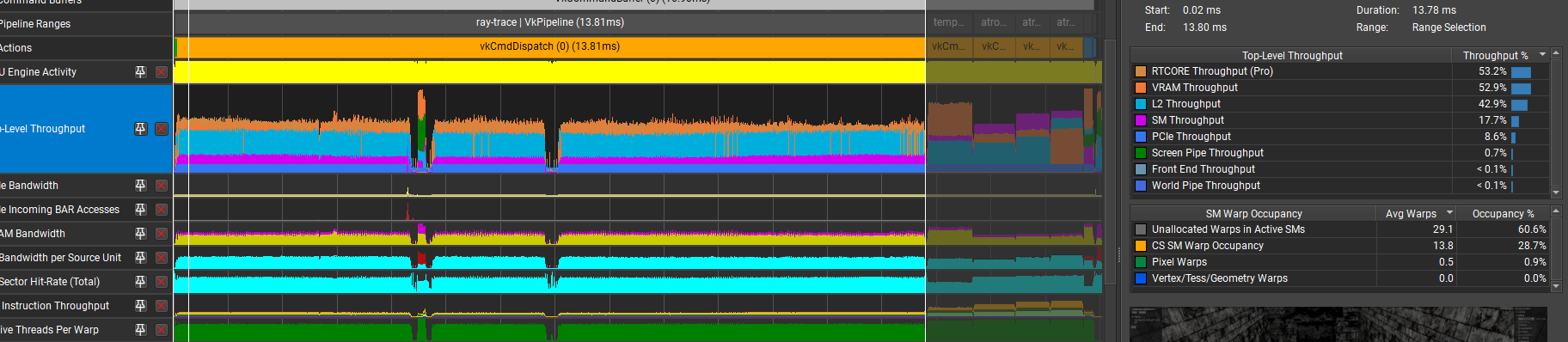
Merging G-buffer with ray-tracing turned out to be a poor optimization. The combined time rose to 13.81ms, which is 1.6ms extra on top of the sum of individual stages:
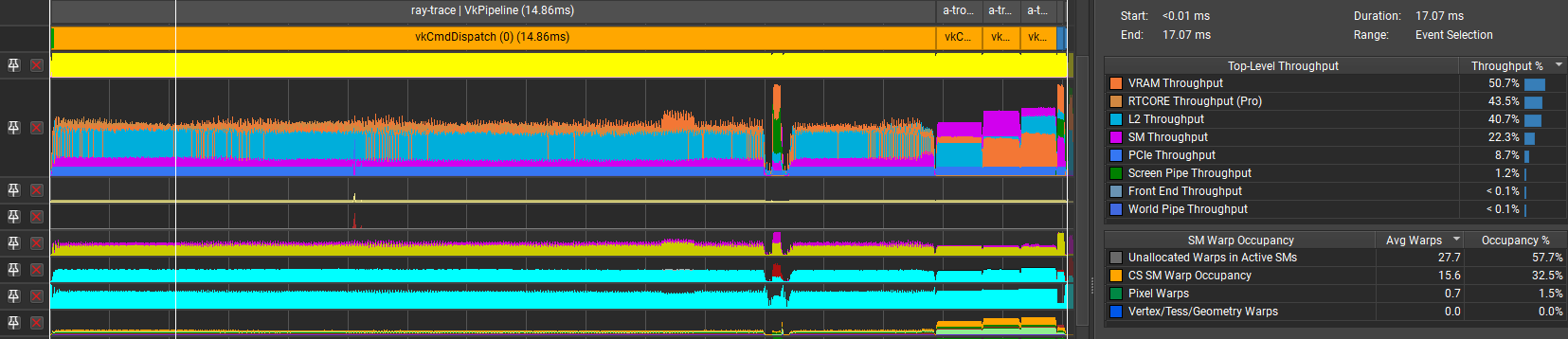
Merging all 3 stages together brought the time up to 14.86ms:
I suspected that one of the cost factors here was the fact that our pixels inside each workgroup would process more diverging surfaces. With each wave/group covering more pixel space, there is more variation to cover. I did an extra test to disable the interleaving and clustering of pixels for groups, and the results were great: G-buffer with ray tracing in total consumed only 9.11ms. If only this was practical for “group-local” approach.
The moral of this story is that ray locality is more important than saving the G-buffer VRAM roundtrip.
Experiment: single loop architecture
One of the metrics shown by NSight that got me interested was “Stalled on No Instructions”. It wasn’t the top offender, but at least I knew how to approach it. When the code is structured like this, we can have unexpected instruction cache misses:
let canonical = compute_canonical();
let temporal = gather_temporal();
let intermediate = reuse_samples(canonical, temporal);
let spatial = gather_spatial();
let final = reuse_samples(intermediate, spatial);
The problem is that, despite reuse_samples being a function called twice, the shader compiler in the driver will inline it in both invocations. So it will have the instructions copied in two different locations. Instead, I reshaped it into a loop:
var final = compute_canonical();
while(..) {
let candidates = is_temporal_iteration ? gather_temporal() : gather_spatial();
final = reuse_samples(final, candidates);
}
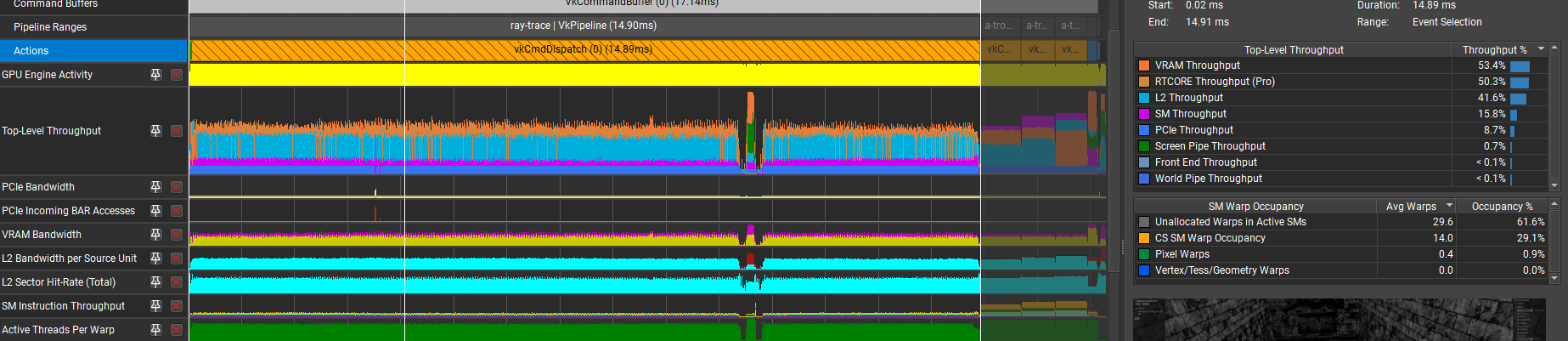
With this, I got around 10% reduction in the “Stalled on No Instructions” metric, but the overall time increased by about 10%:
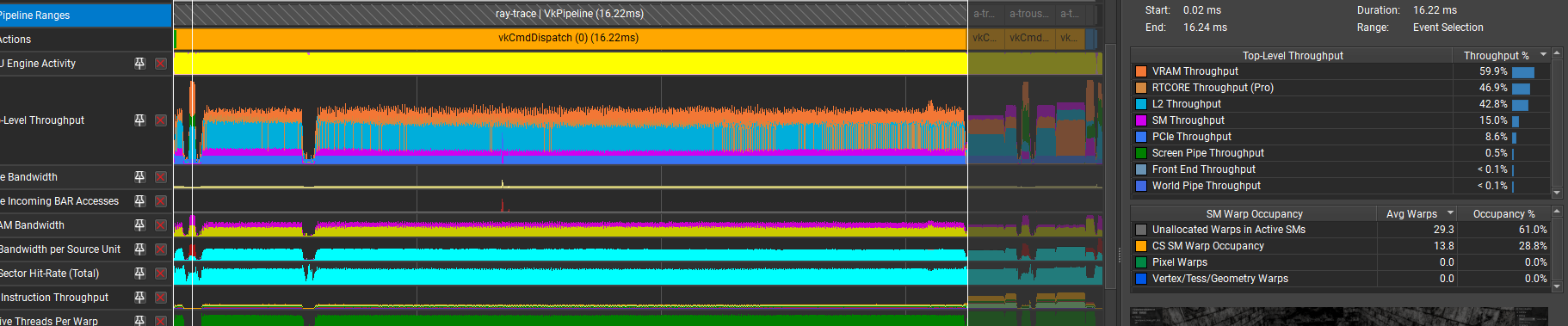
I’m struggling to find an explanation here, other than “the driver isn’t able to optimize this loop as well”.
Experiment: unfused ReSTIR
This idea is not mine, it’s used in NVidia ReSTIR-DI demo code. We can separate temporal and spatial re-use, insert a barrier between them, to allow the spatial to use the results of the temporal. That requires a separate compute pass as well as a VRAM roundtrip. As for the advantages, it’s faster convergence and potentially better occupancy for each of the (lighter) stages.
The implementation can be a bit tricky, since the spatial pass would have largely the same code as the temporal but needs to work on different sets of data (the “previous frame” is the current one). I was happy with the implementation, and here are the results I got. The performance took a hit of about 0.6ms, while convergence didn’t show any difference…
Before:

After:

Perhaps it’s the simplicity of my setup that limited the effectiveness of the approach, or something in the implementation. But overall it didn’t look convincing at the time of testing. Note that having faster convergence (via un-fusing) was also one of the selling points of the original “group-local” ReSTIR approach. It turned out that none of these ideas worked well in practice, but I’ll make sure to re-evaluate them on more complicated models and lighting. At least, now I have a stronger sense of what makes ReSTIR work and what doesn’t. I’d be very interested to learn if similar ideas worked out differently for other people!